Action Coherence Network for Weakly-Supervised Temporal Action Localization
Abstract
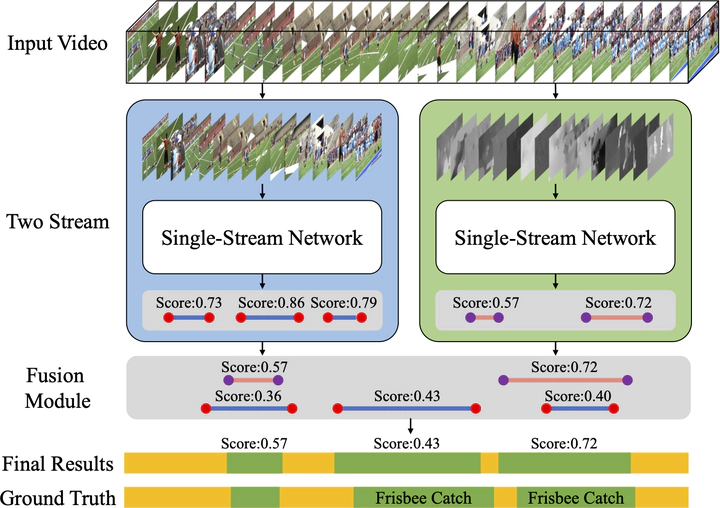
Weakly-supervised Temporal Action Localization (W-TAL) aims at simultaneously classifying and locating all action instances with only video-level supervision. However, current W-TAL methods have two limitations. First, they ignore the difference in video representations between an action instance and its surrounding background when generating and scoring action proposals. Second, the unique characteristics of the RGB frames and optical flow are largely ignored when fusing these two modalities. To address these problems, an Action Coherence Network (ACN) is proposed in this paper. Its core is a new coherence loss which exploits both classification predictions and video content representations to supervise action boundary regression and thus leads to more accurate action localization results. Besides, the proposed ACN explicitly takes into account the specific characteristics of RGB frames and optical flow by training two separate sub-networks, each of which is able to generate modality-specific action proposals independently. Finally, to take advantage of the complementary action proposals generated by two streams, a novel fusion module is introduced to reconcile them and obtain the final action localization results. Experiments on the THUMOS14 and ActivityNet datasets show that our ACN outperforms the state-of-the-art W-TAL methods, and is even comparable to some recent fully-supervised methods. Particularly, ACN achieves a mean average precision of 26.4% on the THUMOS14 dataset under the IoU threshold 0.5.