Adaptive Two-Stream Consensus Network for Weakly-Supervised Temporal Action Localization
Abstract
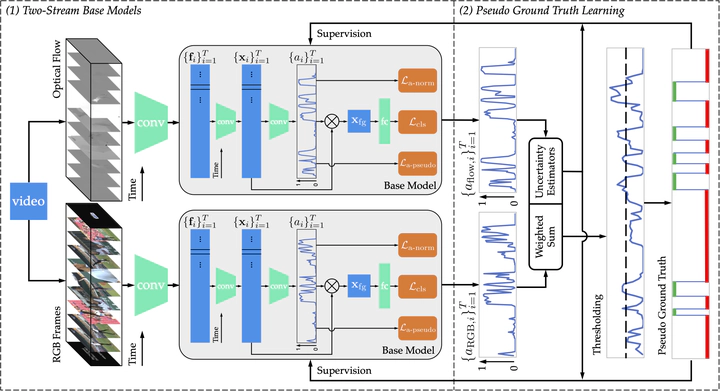
Weakly-supervised temporal action localization (W-TAL) aims to classify and localize all action instances in untrimmed videos under only video-level supervision. Without frame-level annotations, it is challenging for W-TAL methods to clearly distinguish actions and background, which severely degrades the action boundary localization and action proposal scoring. In this paper, we present an adaptive two-stream consensus network (A-TSCN) to address this problem. Our A-TSCN features an iterative refinement training scheme: a frame-level pseudo ground truth is generated and iteratively updated from a late-fusion activation sequence, and used to provide frame-level supervision for improved model training. Besides, we introduce an adaptive attention normalization loss, which adaptively selects action and background snippets according to video attention distribution. By differentiating the attention values of the selected action snippets and background snippets, it forces the predicted attention to act as a binary selection and promotes the precise localization of action boundaries. Furthermore, we propose a video-level and a snippet-level uncertainty estimator, and they can mitigate the adverse effect caused by learning from noisy pseudo ground truth. Experiments conducted on the THUMOS14, ActivityNet v1.2, ActivityNet v1.3, and HACS datasets show that our A-TSCN outperforms current state-of-the-art methods, and even achieves comparable performance with several fully-supervised methods.